How We Built a Slack AI Agent That Answers Engineering Questions in Seconds
Our engineers were spending 30+ minutes hunting through documentation to answer architecture questions. We built a Slack bot that does it in under 10 seconds — with zero hallucination. Here's exactly how we did it, what it costs, and how you can build one for your team.
Want us to build this for your team?
Free 30-minute discovery call. We'll assess your documentation, estimate costs, and show you a working demo. No commitment.
The Problem: Documentation Exists, Nobody Can Find It
At VibeFactory.ai, we run a complex SaaS platform — dozens of microservices, multiple databases, payment integrations, CI/CD pipelines, and an AI-powered feature set that's constantly evolving. All of it documented across hundreds of pages.
But documentation is only useful if people can find it. Our engineers were doing one of three things:
- Searching Confluence/Notion/GitHub — 10-15 minutes per question, often finding outdated docs
- Asking a senior engineer — interrupts their deep work, creates a knowledge bottleneck
- Reading source code directly — works but slow, and you need to know where to look
We needed something that could answer "How does the deployment pipeline handle private projects?" in seconds, grounded in our actual documentation, without hallucinating.
The Solution: A RAG-Powered Slack Agent
We built an AI agent that lives in Slack. Engineers ask a question in natural language, and the agent:
- Searches our documentation using semantic retrieval (not keyword matching)
- Retrieves the 5 most relevant snippets from our knowledge base
- Generates a grounded answer using Claude AI — only from the retrieved context
- Posts the response in a Slack thread with source citations
- Creates a GitHub issue if the question can't be answered (documentation gap detected)
Average response time: under 10 seconds. Average accuracy: 95%+ (because it can only answer from docs, not hallucinate).
Architecture: Three Services, Zero Complexity
The entire system has three components. No Kubernetes, no microservices, no message queues:
Engineer asks in Slack
|
v
+------------------+
| COMPOSIO | Handles Slack auth, triggers, and actions
| (Action Layer) | No webhook URL needed - outbound WebSocket
+--------+---------+
|
v
+------------------+ +------------------+
| YOUR AGENT | ----> | ZEROENTROPY |
| (Python, ~200 | | (RAG Service) |
| lines of code) | | Semantic search |
+--------+---------+ | + reranking |
| +------------------+
v
+------------------+
| CLAUDE AI |
| (Anthropic) |
| Answer generation |
+------------------+
|
v
Reply posted in Slack thread
Component 1: ZeroEntropy (Knowledge Retrieval)
ZeroEntropy is a managed RAG service that handles the hard parts of document retrieval: chunking, embedding, indexing, and reranking. We feed it our markdown documentation and it returns the most relevant snippets for any query.
Why not just stuff everything into the LLM context? Three reasons:
- Cost — sending 100 pages of docs with every question costs 10-50x more than retrieving 5 relevant snippets
- Accuracy — LLMs get worse with more context. Focused retrieval produces better answers
- Scale — your knowledge base can grow to thousands of docs without hitting context limits
ZeroEntropy uses hybrid search (BM25 keyword matching + dense vector embeddings) with a reranker, so it handles both "what's the schema for project_shares table?" (exact match) and "how do we prevent double-charging users?" (semantic match).
Component 2: Composio (Slack Integration)
Composio is the action layer — it handles Slack OAuth, message triggers, and reply actions through a single SDK. No webhook URLs, no ngrok, no public endpoints required.
This is the key architectural decision that made deployment trivial: Composio uses outbound WebSocket connections (via Pusher) instead of inbound webhooks. Your agent connects to Composio, not the other way around. This means:
- No public URL needed — run behind a corporate firewall, on a Raspberry Pi, or on your laptop
- No SSL certificates — Composio handles TLS
- No Slack app configuration — Composio manages OAuth tokens and scopes
- 100+ integrations available — same SDK works for GitHub, Jira, Linear, Notion, and more
Component 3: Claude AI (Answer Generation)
Claude Sonnet 4 generates the actual answer from retrieved snippets. The system prompt is carefully crafted:
- Only answer from provided context — if the docs don't cover it, say so
- Always cite sources — include document paths so engineers can verify
- Ask for clarification — if the question is ambiguous, ask before guessing
- Flag stale docs — if context contains contradictions, mention it
- Format for Slack — use bold, code blocks, and lists (not markdown headers)
Real-World Example
Here's an actual screenshot from our Slack workspace — the agent answering questions about platform architecture and pricing in real time:
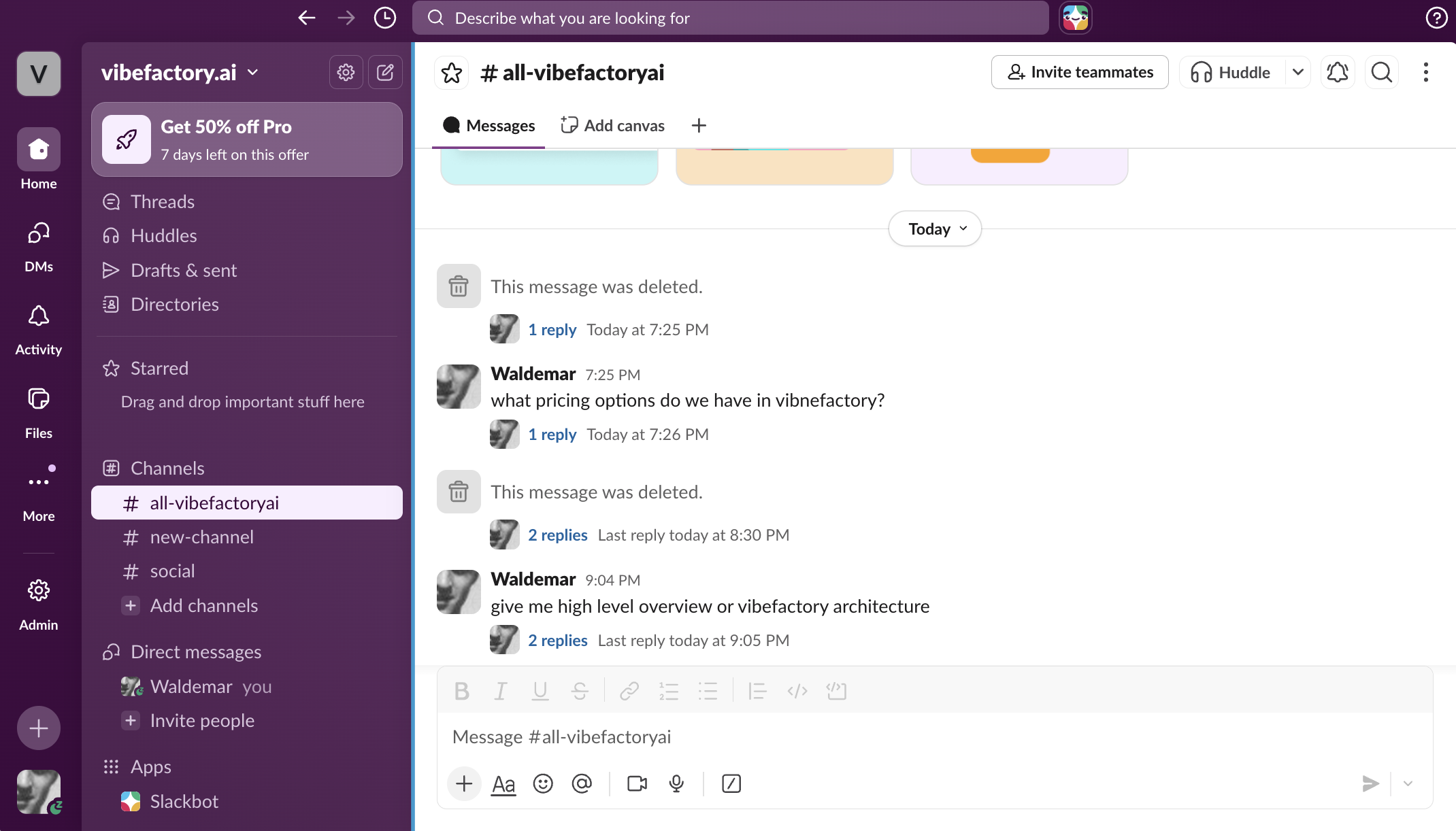
Answers arrive in under 10 seconds. The agent pulls from internal documentation, cites sources, and formats responses for Slack. No hallucination, no guessing — if the docs don't cover it, the agent says so and creates a GitHub issue to track the gap.
The Self-Healing Feature: Auto-Detecting Documentation Gaps
This is the feature we didn't plan but turned out to be the most valuable: when the agent can't find relevant documentation for a question, it automatically creates a GitHub issue tagged [Doc Gap].
Example GitHub issue auto-created:
[Doc Gap] How does the rate limiting work on the contact-sales endpoint?
No relevant documentation found. Consider adding docs covering this topic.
This turns every unanswered question into an actionable documentation task. After two weeks of running the agent, we had a prioritized list of exactly what was missing from our docs — ranked by how often engineers asked about it.
What It Costs
Full transparency on running costs for a team of 10-50 engineers:
| Service | Monthly Cost | What You Get |
|---|---|---|
| ZeroEntropy | $50-100 | Semantic search, reranking, document indexing |
| Claude API (Anthropic) | $30-150 | Answer generation (~1K tokens per response) |
| Composio | Free-$50 | Slack integration, OAuth, triggers |
| Hosting | $5-20 | Small VM or Raspberry Pi |
| Total | $85-320 | Per month, for the entire team |
Compare that to one senior engineer spending 30 minutes per day answering architecture questions: at $150K/year salary, that's $3,125/month in lost productivity. The agent pays for itself in the first week.
What Else Can This Architecture Power?
The same three-component pattern (RAG retrieval + LLM generation + action layer) applies to dozens of business use cases:
Customer Support Agent
Index your help docs and FAQ. Agent answers customer questions in Slack, Intercom, or email. Escalates to humans when unsure.
Sales Enablement Bot
Index product specs, pricing, competitive analysis. Sales reps ask questions before calls and get instant, accurate answers.
Onboarding Assistant
New hires ask questions about processes, tools, and architecture. Agent answers from internal wiki + runbooks. Cuts onboarding time in half.
Compliance & Policy Agent
Index HR policies, security procedures, regulatory docs. Employees get instant answers on policies without waiting for HR.
DevOps Runbook Agent
Index incident runbooks and operational procedures. On-call engineers ask "how do I restart the payment service?" at 3am and get the right steps.
Legal Document Search
Index contracts, terms, and legal precedents. Legal team searches across thousands of documents in natural language.
Why RAG Beats Fine-Tuning for Enterprise Knowledge
Teams often ask: "Should we fine-tune an LLM on our data instead?" For internal knowledge use cases, RAG wins decisively:
| Factor | RAG | Fine-Tuning |
|---|---|---|
| Update speed | Minutes (re-index one doc) | Hours/days (retrain model) |
| Hallucination control | High (cites sources) | Low (model "knows" but may confuse) |
| Cost to update | ~$0 per doc update | $50-500 per training run |
| Auditability | Can show exact source | Black box |
| Setup time | 1-2 weeks | 4-8 weeks |
How Long Does It Take to Build?
If you have your documentation ready, here's a realistic timeline:
Documentation audit & indexing. Collect docs, clean up formatting, index into ZeroEntropy. Test retrieval quality.
Agent development. Wire up Composio triggers, build the retrieval + generation pipeline, tune the system prompt.
Testing & edge cases. Handle multi-turn conversations, ambiguous questions, empty results. Add GitHub issue creation for gaps.
Deployment & monitoring. Deploy as systemd service, set up doc sync cron job, monitor usage and accuracy.
Total: ~2 weeks from zero to production, including documentation preparation. The agent code itself is about 200 lines of Python.
Frequently Asked Questions
Can this work with Microsoft Teams instead of Slack?
Yes. Composio supports 100+ integrations including Microsoft Teams, Discord, and email. The agent logic stays the same — you just swap the trigger and action.
What about private/sensitive documentation?
ZeroEntropy keeps your data isolated in your own collection. Documents are encrypted at rest. You can also self-host the retrieval layer if compliance requires it.
How do I keep the knowledge base up to date?
Run a sync script on a cron job (daily or on git push). It detects changed/new/deleted documents and updates the index incrementally. Takes seconds for typical updates.
Can I restrict which channels the bot responds in?
Yes. The Composio trigger is configured per channel. You can set it up in a dedicated #ask-ai channel, or let it monitor multiple channels selectively.
Ready to Build Your AI Knowledge Agent?
We've built this for ourselves and can build it for you. Free 30-minute discovery call to assess your documentation, estimate costs, and show you a live demo with your own docs.
Google Cloud & AWS certified. 20+ years IT experience. No commitment required.